OLAP SQL dengan DuckDB untuk Analisis Data terhadap kumpulan file Apache Parquet
Kita bisa melakukan OLAP sintaks SQL dengan DuckDB terhadap kumpulan file Apache Parquet. Kita akan menggunakan data-set terbuka NYC Yellow Taxi selama tahun 2022 untuk bahan uji coba.

OLAP biasanya digunakan untuk menghitung agregat dan mendapatkan angka-angka untuk pembuatan laporan. Di sisi lain, SQL adalah sintaks deklaratif yang relatif mudah dan sangat nyaman digunakan. Kali ini saya akan membagikan contoh penggunaan DuckDB untuk analisis data OLAP terhadap kumpulan file Apache Parquet.
Disclaimer: tulisan ini adalah eksplorasi yang bersifat eksperimental dan hanya hasil kreatif penulis yang tidak ada kaitannya dengan tempat bekerja sekarang dan juga sebelumnya; Anda bisa membaca halaman Disclaimer di situs ini untuk penyangkalan yang lengkap.
Pendahuluan
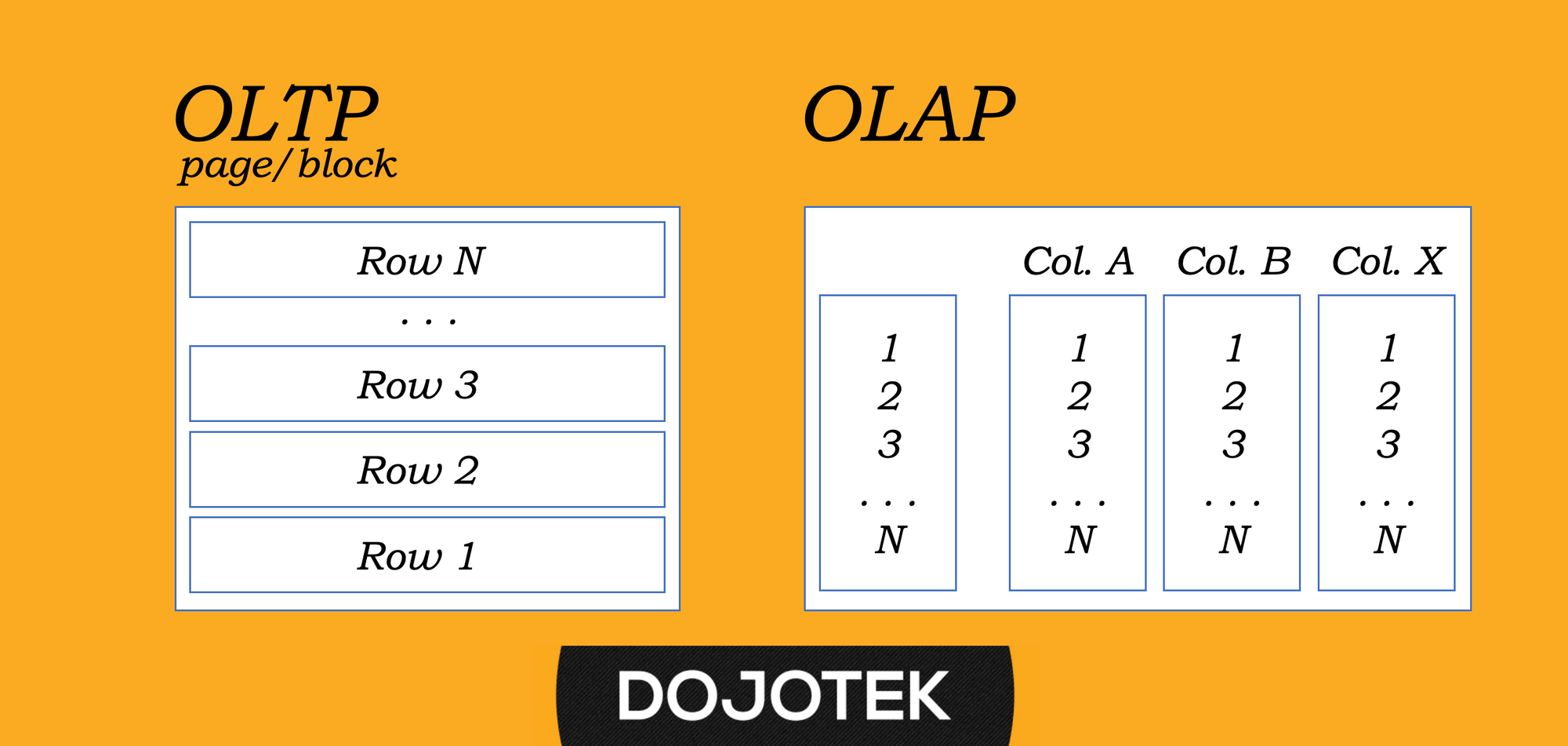
Sistem teknologi informasi sangat lekat dengan penggunaan basis-data untuk penyimpanan dan pengolahan informasi. Secara umum kita mengenal dua kategori yaitu OLTP (online transactional processing) dan OLAP (online analytical processing). Keduanya menjawab kebutuhan operasional bisnis yang berbeda.
Hal teknis fundamental yang membedakan keduanya adalah bagaimana baris-baris data disimpan secara fisik di berkas dan blok media menyimpanan; secara sederhananya basis-data OLTP akan menyimpan data dengan orientasi baris per baris, sedangkan basis-data OLAP akan menyimpan dengan orientasi kolom per kolom.
DuckDB adalah sebuah sistem manajemen basis-data SQL OLAP dalam sebuah proses. Sebuah kakas yang bisa membantu analisis data, termasuk kumpulan file Apache Parquet, dalam skala yang relatif kecil (jika dibandingkan dengan Apache Spark, Trino, Apache Pinot dan sejenisnya). Sederhananya Anda bisa membayangkan perbandingan antara SQLite dengan PostgreSQL, MySQL, dan Oracle.
Dalam eksplorasi kali ini kita akan menggunakan data-set terbuka dari NYC TLC (New York City - Taxi and Limousine Commission). Dalam eksperimen kali ini kita hanya mengambil data Yellow Taxi selama tahun 2022, mengandung sekitar 39 juta data perjalanan taksi. Lalu kita akan menjalankan beberapa contoh SQL query untuk mendapatkan informasi berharga.
Persiapan
Hal pertama yang perlu dilakukan adalah melakukan instalasi DuckDB:
- untuk sistem operasi Windows, saya asumsikan Anda terbiasa dengan GUI (graphical user interface) maka saya merekomendasikan untuk menggunakan aplikasi DBeaver dan memasang plugin DuckDB (referensi)
- untuk sistem operasi Linux dan MacOS, saya asumsikan Anda terbiasa dengan CLI (command-line-interface) maka Anda bisa mengunduh langsung single-binary dari situs DuckDB (referensi)
Saya sendiri kali ini menggunakan sistem operasi Windows, lalu memasang DBeaver dan plugin DuckDB.
Selanjutnya Anda dapat mengunduh berkas-berkas Apache Parquet yang diperlukan (referensi). Pada eksperimen kali ini kita akan menggunakan "Yellow Taxi Trip Records" selama tahun 2022. Pola URL file Parquet-nya kurang lebih:
https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2022-01.parquet
. . .
https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2022-12.parquetSaya sendiri menyimpan kumpulan file Apache Parquet untuk eksplorasi kali ini di folder berikut:
C:/analytics-data-set/nyc-taxi-yellow-2022/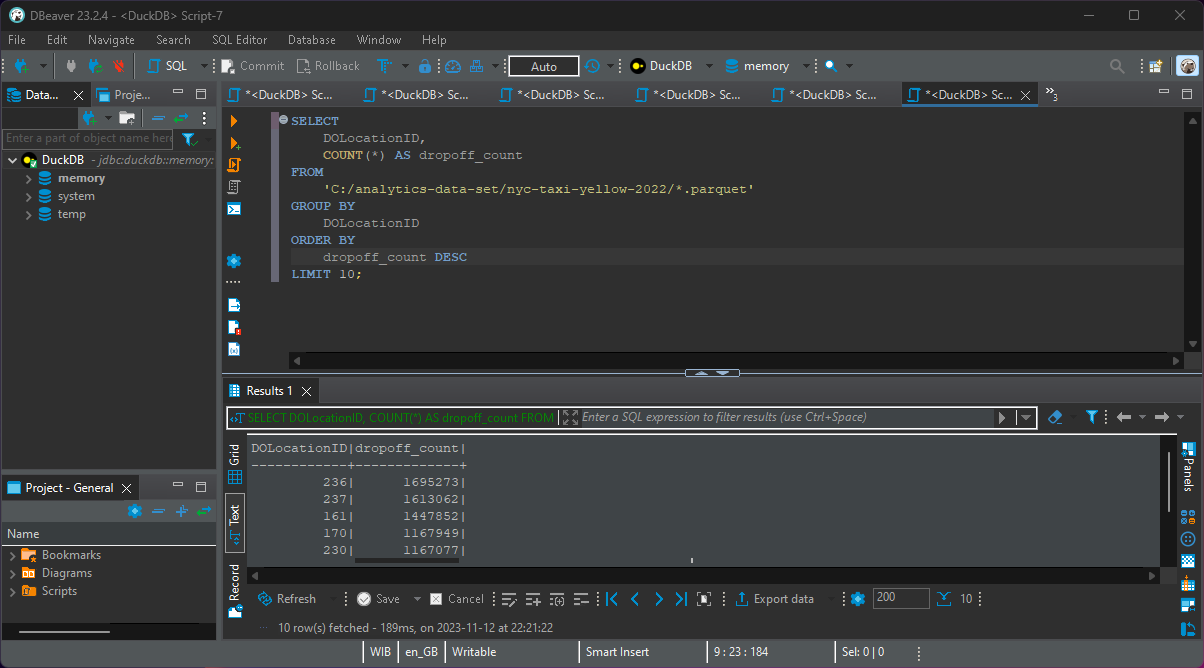
Analisis 1 - menghitung omset setiap per bulan
Query SQL untuk DuckDB:
SELECT
EXTRACT(YEAR FROM tpep_pickup_datetime) AS the_year,
EXTRACT(MONTH FROM tpep_pickup_datetime) AS the_month,
CAST(SUM(total_amount) AS INTEGER) AS total_revenue
FROM
'C:/analytics-data-set/nyc-taxi-yellow-2022/*.parquet'
WHERE
the_year = 2022
GROUP BY
the_year, the_month
ORDER BY
the_year, the_month;Keluaran dari DuckDB:
the_year|the_month|total_revenue|
--------+---------+-------------+
2022| 1| 47231556|
2022| 2| 58091929|
2022| 3| 74711797|
2022| 4| 76281854|
2022| 5| 79223952|
2022| 6| 78688869|
2022| 7| 68043359|
2022| 8| 67952762|
2022| 9| 72136987|
2022| 10| 81767989|
2022| 11| 71786387|
2022| 12| 83465813|Dari keluaran DuckDB, kita mengetahui omset selama Januari 2022 adalah sekitar $47 juta US (sekitar Rp 737 milyar).
Analisis 2 - mengetahui lokasi pick-up dan drop-off paling populer
Query SQL untuk DuckDB:
SELECT
PULocationID,
COUNT(*) AS pickup_count
FROM
'C:/analytics-data-set/nyc-taxi-yellow-2022/*.parquet'
GROUP BY
PULocationID
ORDER BY
pickup_count DESC
LIMIT 10;Keluaran dari DuckDB:
PULocationID|pickup_count|
------------+------------+
132| 1915375|
237| 1858969|
236| 1656140|
161| 1573000|
142| 1296787|
186| 1294002|
162| 1291995|
230| 1220491|
170| 1213881|
48| 1206218|Sekedar informasi, 8 lokasi pick-up paling populer antara lain:
- lokasi 132 adalah
"Queens","JFK Airport" - lokasi 236 dan 237 adalah
"Manhattan","Upper East Side North" - lokasi 161 adalah
"Manhattan","Midtown Center" - lokasi 142 adalah
"Manhattan","Lincoln Square East" - lokasi 186 adalah
"Manhattan","Penn Station/Madison Sq West" - lokasi 162 adalah
"Manhattan","Midtown Center" - lokasi 230 adalah
"Manhattan","Times Sq/Theatre District"
Analisis 3 - mengetahui lokasi drop-off paling populer
Query SQL untuk DuckDB:
SELECT
DOLocationID,
COUNT(*) AS dropoff_count
FROM
'C:/analytics-data-set/nyc-taxi-yellow-2022/*.parquet'
GROUP BY
DOLocationID
ORDER BY
dropoff_count DESC
LIMIT 10;Keluaran dari DuckDB:
DOLocationID|dropoff_count|
------------+-------------+
236| 1695273|
237| 1613062|
161| 1447852|
170| 1167949|
230| 1167077|
239| 1096034|
142| 1085751|
141| 1070372|
48| 1065448|
162| 1052308|Sekeder informasi, 8 lokasi drop-off paling populer antara lain:
- lokasi 236 dan 237 adalah
"Manhattan","Upper East Side North" - lokasi 161 adalah
"Manhattan","Midtown Center" - lokasi 170 adalah
"Manhattan","Murray Hill" - lokasi 230 adalah
"Manhattan","Times Sq/Theatre District" - lokasi 239 adalah
"Manhattan","Upper West Side South" - lokasi 142 adalah
"Manhattan","Lincoln Square East" - lokasi 141 adalah
"Manhattan","Lenox Hill West"
Analisis 4 - identifikasi jam paling sibuk untuk permintaan taksi New York
Query SQL untuk DuckDB:
SELECT
EXTRACT(HOUR FROM tpep_pickup_datetime) AS the_hour,
COUNT(*) AS pickup_count
FROM
'C:/analytics-data-set/nyc-taxi-yellow-2022/*.parquet'
GROUP BY
the_hour
ORDER BY
pickup_count DESC
LIMIT 10;Keluaran dari DuckDB:
the_hour|pickup_count|
--------+------------+
18| 2798619|
17| 2668468|
19| 2533782|
15| 2478428|
16| 2459296|
14| 2416452|
13| 2260701|
12| 2213324|
20| 2188858|
21| 2103776|Dari hasil analisis dapat diketahui 3 jam paling sibuk adalah pukul 6 sore, 5 sore, dan 7 malam.
Analisis 5 - hitung rerata tips untuk setiap metode pembayaran
Query SQL untuk DuckDB:
SELECT
payment_type,
AVG(tip_amount / total_amount) * 100 AS average_tip_percentage
FROM
'C:/analytics-data-set/nyc-taxi-yellow-2022/*.parquet'
WHERE
total_amount > 0
GROUP BY
payment_type;Keluaran dari DuckDB:
payment_type|average_tip_percentage|
------------+----------------------+
1| 15.335375311679389|
0| 167.3618926285395|
4| 0.03492074472023569|
2| 0.001599945031078535|
5| 0.0|
3| 0.06088984113530848|Sekedar informasi:
- payment_type 1 adalah kartu kredit, dengan rerata tips $15 US
- payment_type 0 tidak ada keterangan dari NYC TLC (mungkin data kotor)
- sedangkan sisa-nya tidak terlalu menarik
Analisis 6 - hitung rerata jumlah penumpang per trip setiap bulan
Query SQL untuk DuckDB:
SELECT
EXTRACT(YEAR FROM tpep_pickup_datetime) AS the_year,
EXTRACT(MONTH FROM tpep_pickup_datetime) AS the_month,
AVG(passenger_count) AS average_passenger_count
FROM
'C:/analytics-data-set/nyc-taxi-yellow-2022/*.parquet'
WHERE
the_year = 2022
GROUP BY
the_year, the_month
ORDER BY
the_year, the_month;Keluaran dari DuckDB:
the_year|the_month|average_passenger_count|
--------+---------+-----------------------+
2022| 1| 1.3894357834422966|
2022| 2| 1.3921306774447897|
2022| 3| 1.3890248467696122|
2022| 4| 1.4138605032766183|
2022| 5| 1.393918007799309|
2022| 6| 1.3990664606667438|
2022| 7| 1.4293598690720517|
2022| 8| 1.4230679975943938|
2022| 9| 1.3863100190662991|
2022| 10| 1.3846952533232157|
2022| 11| 1.3929432026963835|
2022| 12| 1.4195750996686014|